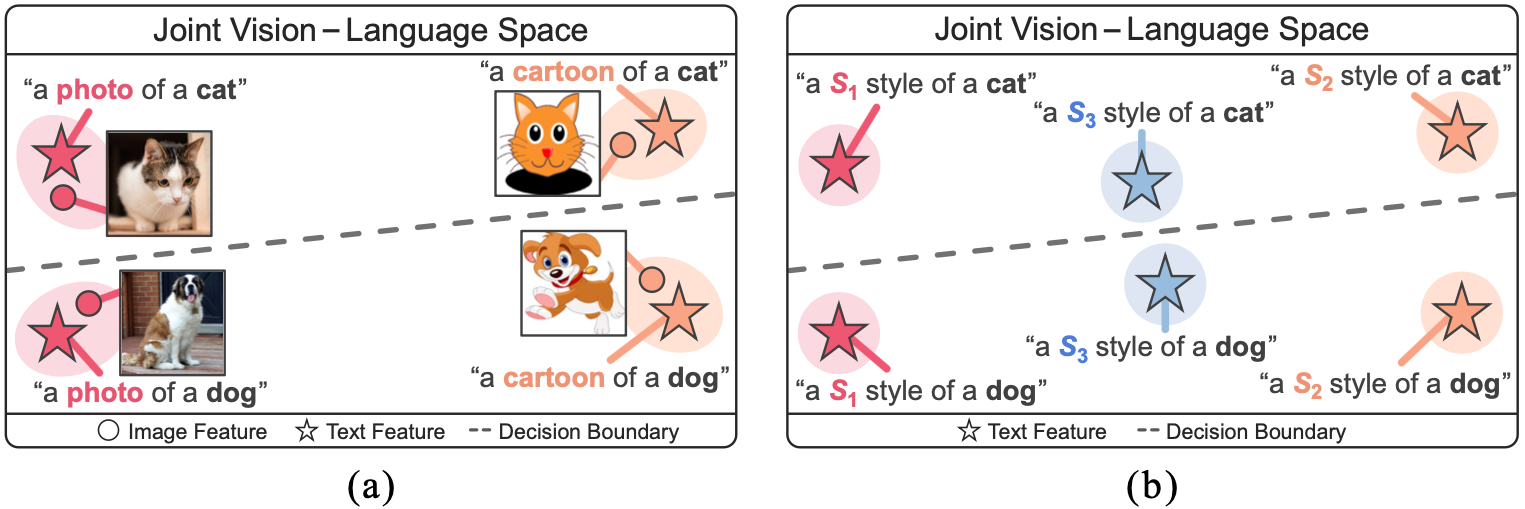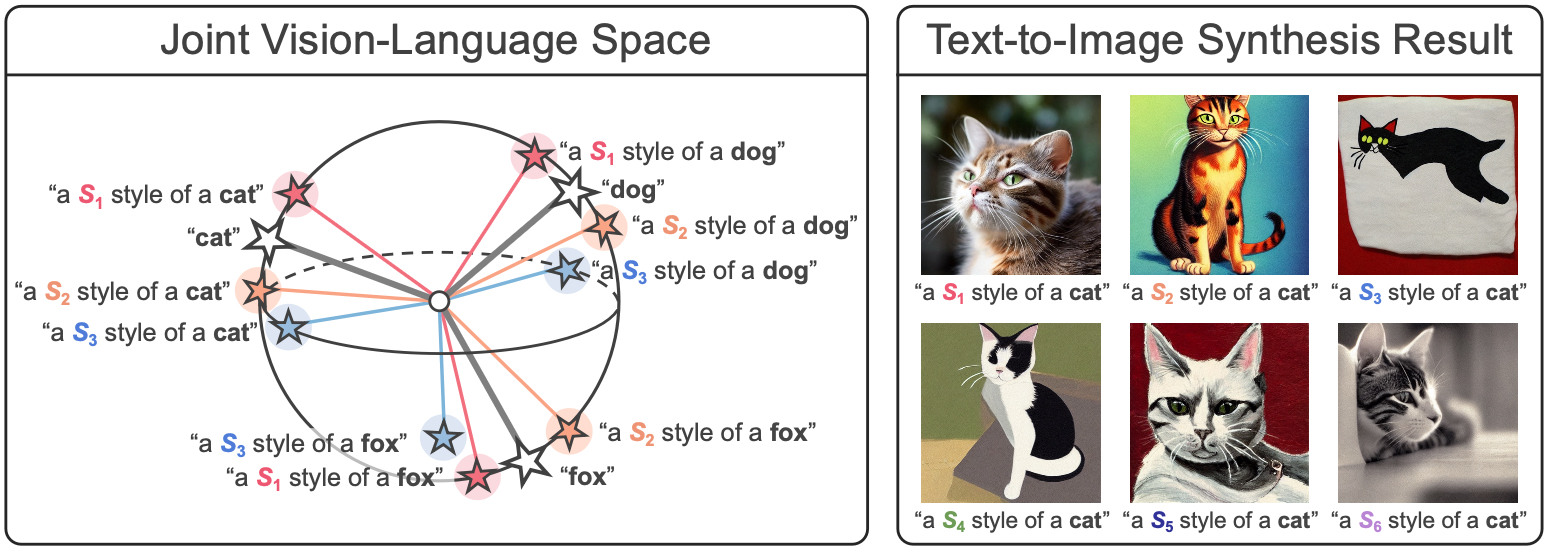
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Also, a recent study has demonstrated the cross-modal transferability phenomenon of this joint space. From these observations, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization.
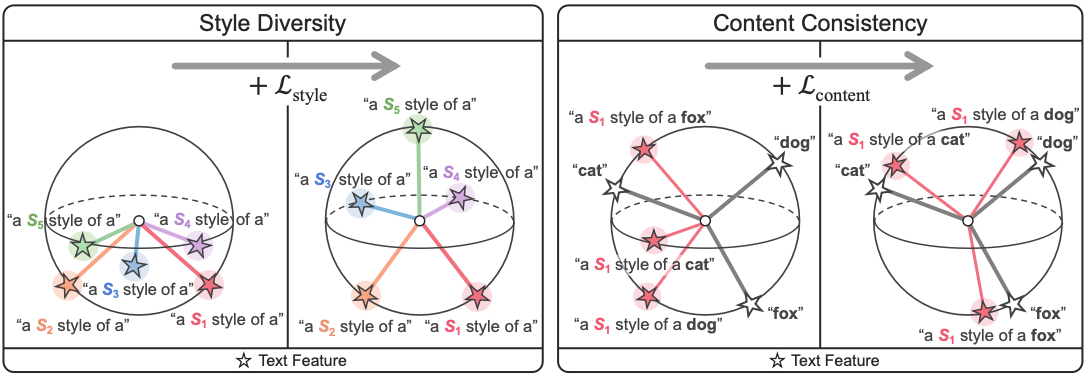
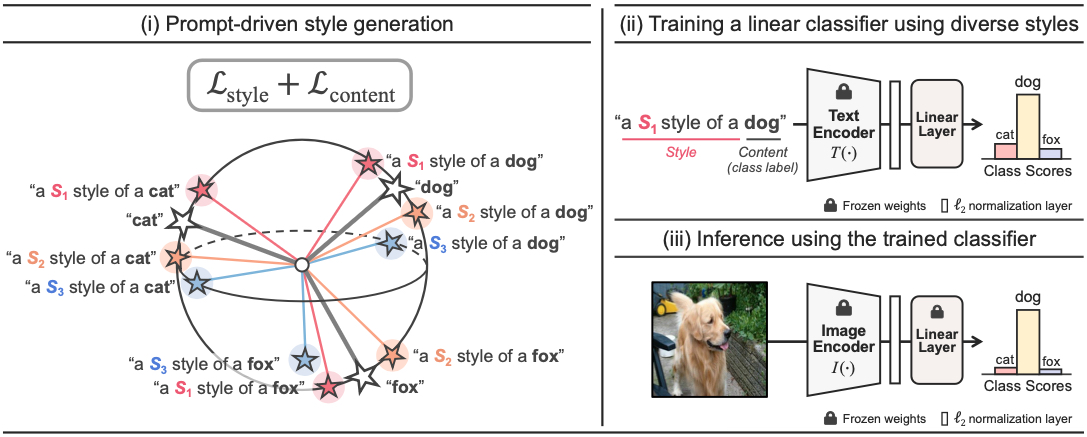
The proposed method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features.
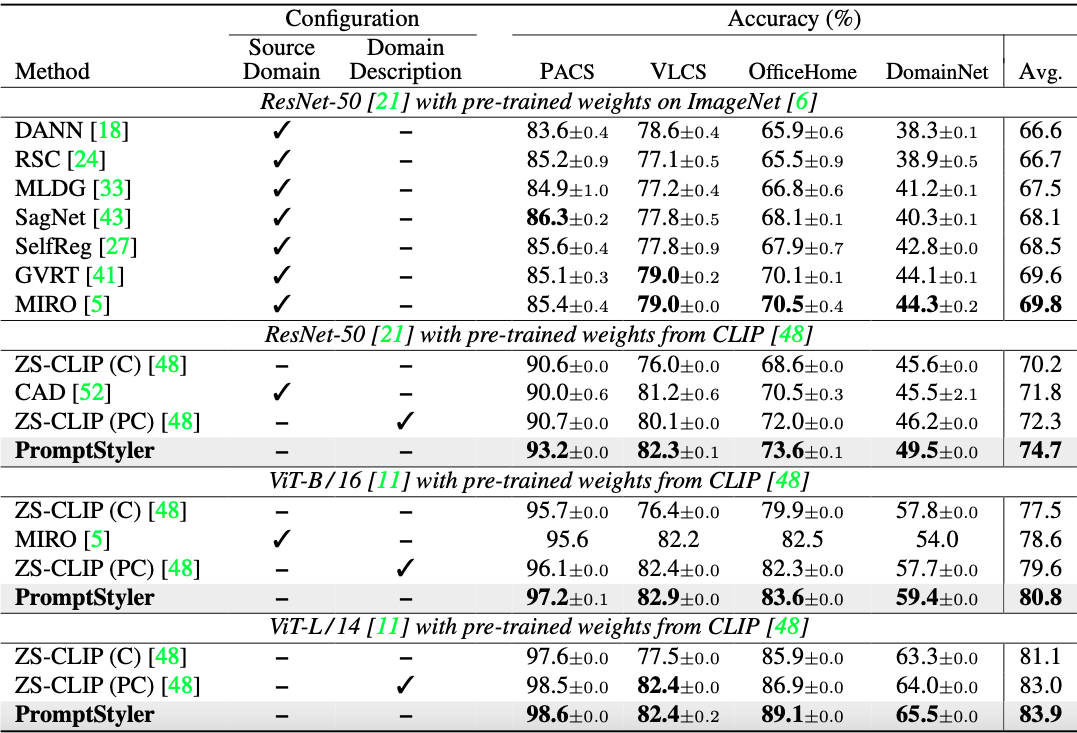
PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, even though it does not require any images for training.
Figure 1. (a) Text features could effectively represent various image styles in a joint vision-language space. (b) PromptStyler synthesizes diverse styles in a joint vision-language space via learnable style word vectors for pseudo-words S* without using any images.
We notice that a large-scale pre-trained model might have already observed a great variety of domains and thus can be used as an efficient proxy of actual multiple source domains. From this perspective, we raised a question "Could we further improve model's generalization capability by simulating various distribution shifts in the latent space of such a large-scale model without using any source domain data?"
In this paper, we propose a prompt-driven style generation method, dubbed PromptStyler, which synthesizes diverse styles via learnable word vectors to simulate distribution shifts in a hyperspherical joint vision-language space. PromptStyler is motivated by the observation that a shared style of images could characterize a domain and such a shared style could be captured by a learnable word vector for a pseudo-word S* using CLIP with a prompt ("a painting in the style of S*").
Figure 2. Important factors in the proposed method. PromptStyler learns style word vectors for pseudo-words S* which lead to diverse style features (from "a S* style of a") while preserving content information encoded in style-content features (from "a S* style of a [class]"). Our method maximizes style diversity and content consistency in a hyperspherical joint vision-language space (e.g., CLIP latent space).
Figure 3. PromptStyler learns diverse style word vectors which do not distort content information of style-content prompts. After learning style word vectors, we synthesize style-content features (e.g., from "a S1 style of a dog") via a pre-trained text encoder for training a linear classifier. The classifier is trained by a classification loss using those synthesized features and their corresponding class labels (e.g., "dog"). At inference time, a pre-trained image encoder extracts image features, which are fed as input to the trained classifier. Note that the encoders are derived from the same vision-language model (e.g., CLIP).
Table 2. Comparison with the state-of-the-art domain generalization methods. ZS-CLIP (C) denotes zero-shot CLIP using "[class]" as its text prompt, and ZS-CLIP (PC) indicates zero-shot CLIP using "a photo of a [class]" as its text prompt. Note that PromptStyler does not exploit any source domain data and domain descriptions.
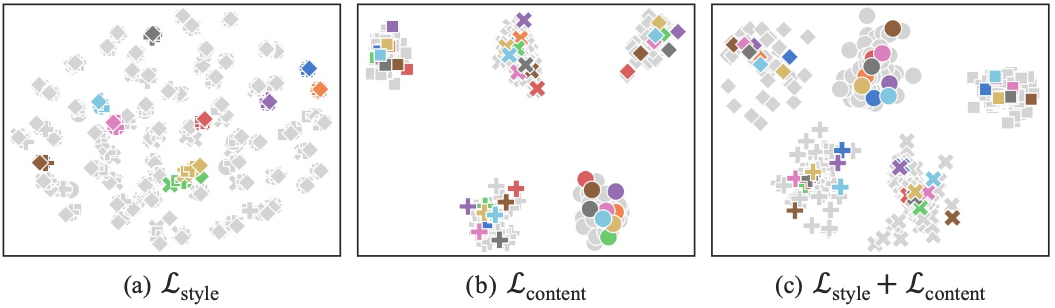
Figure 4. t-SNE visualization results for the target task VLCS (5 classes) using synthesized style-content features. We visualize such features obtained from the learned 80 style word vectors and all the 5 classes (bird, car, chair, dog, person). Different colors denote features obtained from different style word vectors, and different shapes indicate features obtained from different class names. We only colorize features from the first 10 styles. Combining the style diversity loss and content consistency loss leads to diverse styles while preserving content information.
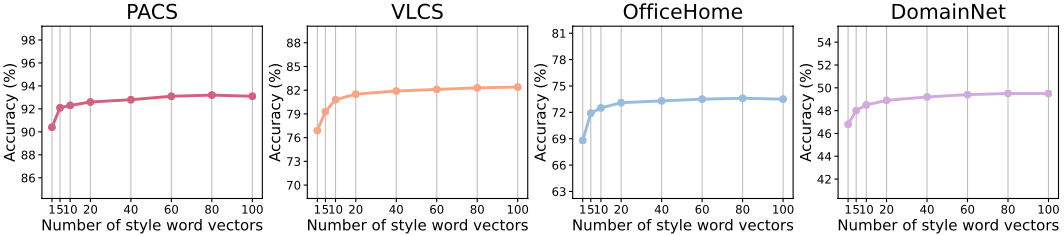
Figure 6. Top-1 classification accuracy on the PACS, VLCS, OfficeHome and DomainNet datasets with regard to the number of learnable style word vectors.
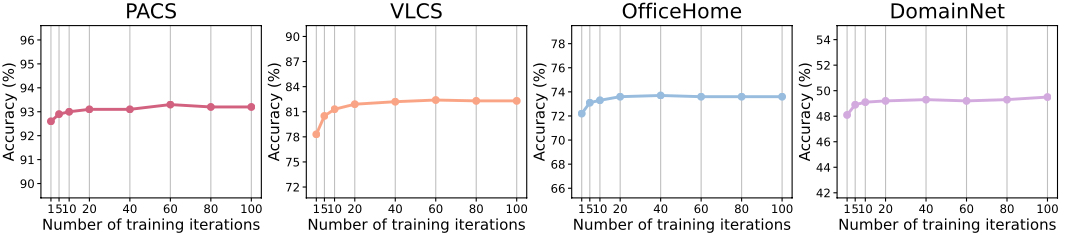
Figure 7. Top-1 classification accuracy on the PACS, VLCS, OfficeHome and DomainNet datasets with regard to the number of training iterations for learning each style word vector.
PromptStyler (PromptStyler.official@gmail.com)
@InProceedings{cho2023PromptStyler,
title={PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization},
author={Junhyeong Cho and Gilhyun Nam and Sungyeon Kim and Hunmin Yang and Suha Kwak},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2023}
}